










 Signs MoU with Central Reserve Police Force Family Welfare Association to Offer Scholarships and Mentorship Support to CRPF Families")






















Accelerating data driven discoveries
Accelerating data driven discoveries. Life science companies use Paradigm4’s unique database management system to uncover new insights into human health.
As technologies like single-cell genomic sequencing, enhanced biomedical imaging, and medical “internet of things” devices proliferate, key discoveries about human health are increasingly found within vast troves of complex life science and health data. But drawing meaningful conclusions from that data is a difficult problem that can involve piecing together different data types and manipulating huge data sets in response to varying scientific inquiries.

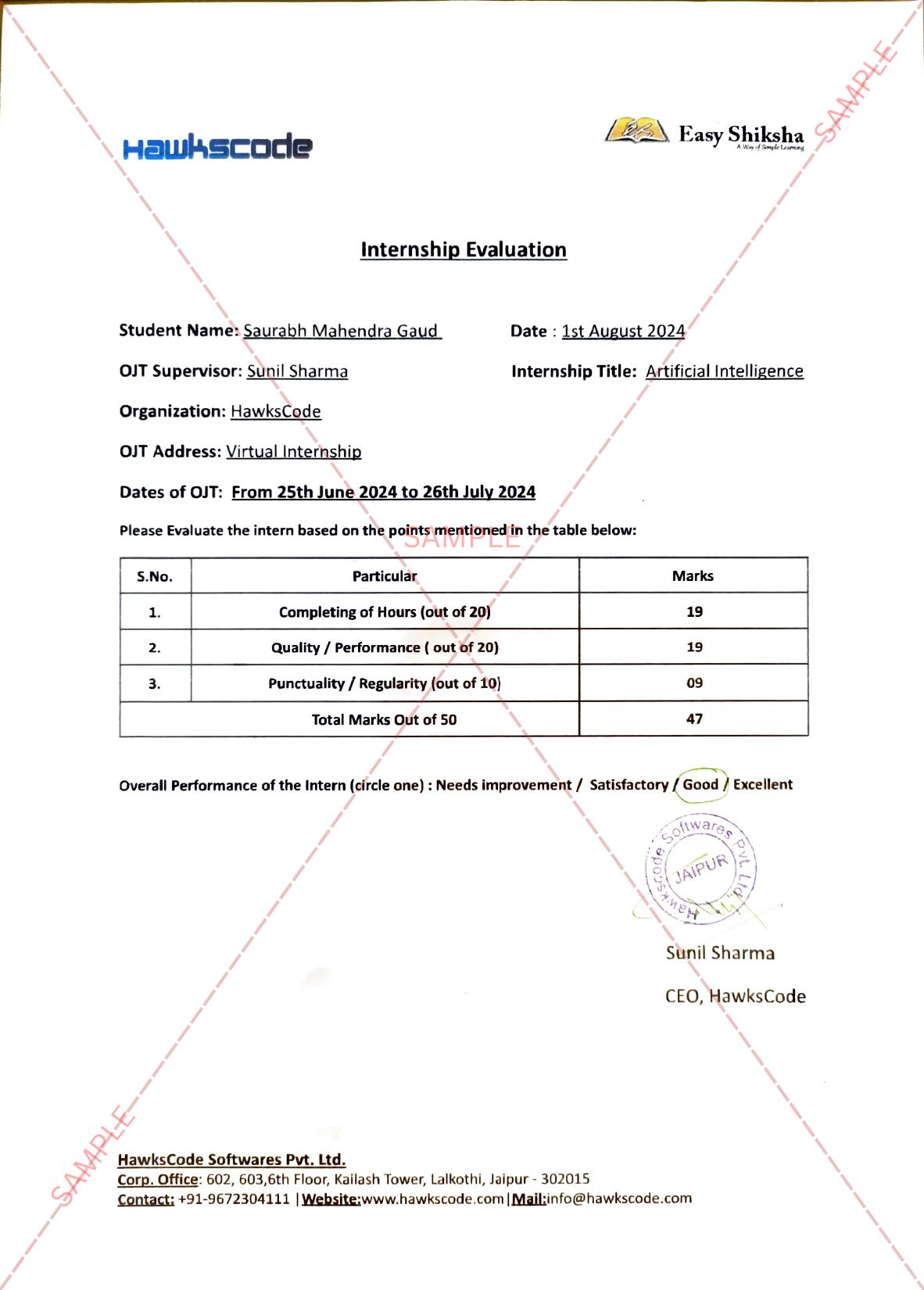
Important Announcement – EasyShiksha has now started Online Internship Program “Ab India Sikhega Ghar Se”
Stonebraker has been a pioneer in the field of database management systems for decades. He has started nine companies, and his innovations have set standards for the way modern systems allow people to organize and access large data sets. Much of Stonebraker’s career has focused on relational databases, which organize data into columns and rows. But in the mid 2000s, Stonebraker realized that a lot of data being generated would be better stored not in rows or columns but in multidimensional arrays.
For example, satellites break the Earth’s surface into large squares, and GPS systems track a person’s movement through those squares over time. That operation involves vertical, horizontal, and time measurements that aren’t easily grouped or otherwise manipulated for analysis in relational database systems. “[Relational database systems] scan either horizontally or vertically, but not both,” Stonebraker explains. “So you need a system that does both, and that requires a storage manager down at the bottom of the system which is capable of moving both horizontally and vertically through a very big array. That’s what Paradigm4 does.”
Top Courses in Software Engineering















More Courses With Certification
Today Paradigm4’s customers include some of the biggest pharmaceutical and biotech companies in the world as well as research labs at the National Institutes of Health, Stanford University, and elsewhere.
Customers can integrate genomic sequencing data, biometric measurements, data on environmental factors, and more into their inquiries to enable new discoveries across a range of life science fields.
In the life sciences, however, the founders believe they already have a revolutionary product that’s enabling a new world of discoveries. Down the line, they see SciDB and REVEAL contributing to national and worldwide health research that will allow doctors to provide the most informed, personalized care imaginable.
“The query that every doctor wants to run is, when you come into his or her office and display a set of symptoms, the doctor asks, ‘Who in this national database has genetics that look like mine, symptoms that look like mine, lifestyle exposures that look like mine? And what was their diagnosis? What was their treatment? And what was their morbidity?” Stonebraker explains. “This is cross correlating you with everybody else to do very personalized medicine, and I think this is within our grasp.”
I hope you like this blog, Accelerating data driven discoveries. To learn more visit HawksCode and Easyshiksha.
Empower your team. Lead the industry
Get a subscription to a library of online courses and digital learning tools for your organization with EasyShiksha
Request NowALSO READ: Ampersand-group-successfully-concludes-teacher-training
Get Course: Web-Development-with-PHP-MySQL-Database







 Signs MoU with Central Reserve Police Force Family Welfare Association to Offer Scholarships and Mentorship Support to CRPF Families")













{kind=link}
{kind=link}
{kind=link}